Il riflesso condizionato del catastrofismo alimenta ancora le speranze di molte testate, anche famose. Ma non succederà di nuovo.
Parliamo di fatti ed eventi recentissimi. Pochi giorni fa è scattato il protocollo d’emergenza presso l’Ospedale Sacco di Milano per due presunti casi di Ebola rilevati su cooperanti rientrati dall’Uganda: i titoli sono volati alti, il panico da bacheca si è attivato immediatamente, per poi sgonfiarsi poche ore più tardi quando i test ufficiali del Ministero della Salute hanno confermato la totale negatività delle analisi, riconducendo il tutto a una comune gastroenterite (trovate la smentita ufficiale del caso su L’Unione Sarda). Sempre in questo mese, i fari mediatici si erano accesi su un focolaio di patologie respiratorie scoppiato a bordo di una nave da crociera, il famigerato Hantavirus, su cui subito la maggioranza delle testate, anche molto blasonate, si sono buttate a capofitto cercando di trasformarla nella nuova emergenza globale. Tutto questo ignorando allegramente il fatto più importante: gli infettivologi hanno subito chiarito che il rischio reale per la popolazione rimaneva eccezionalmente basso (come spiegato nel dettaglio medico da Humanitas).
Che cosa ci dicono questi episodi ravvicinati? Ci dicono che una parte consistente dell’editoria digitale italiana soffre di un riflesso condizionato tristemente evidente. Il trauma di fondo è la fine del biennio 2020-2021: un’epoca d’oro in cui i siti di informazione registravano numeri di traffico astronomici e lettori totalmente ipnotizzati da ogni singolo aggiornamento sanitario. Oggi quei numeri sono passati, ma la ricerca di un nuovo mammellone a cui attaccarsi continua. Ogni volta che su una nave salta fuori una malattia tropicale o un termometro sale in un reparto infettivi, nelle redazioni si attiva una tendenza disperata: tentare di replicare artificialmente il successo editoriale del COVID-19, gonfiando la narrazione oltre ogni limite oggettivo. Ma le persone si sono semplicemente annoiate.
I dati della disperazione: perché i publisher urlano?
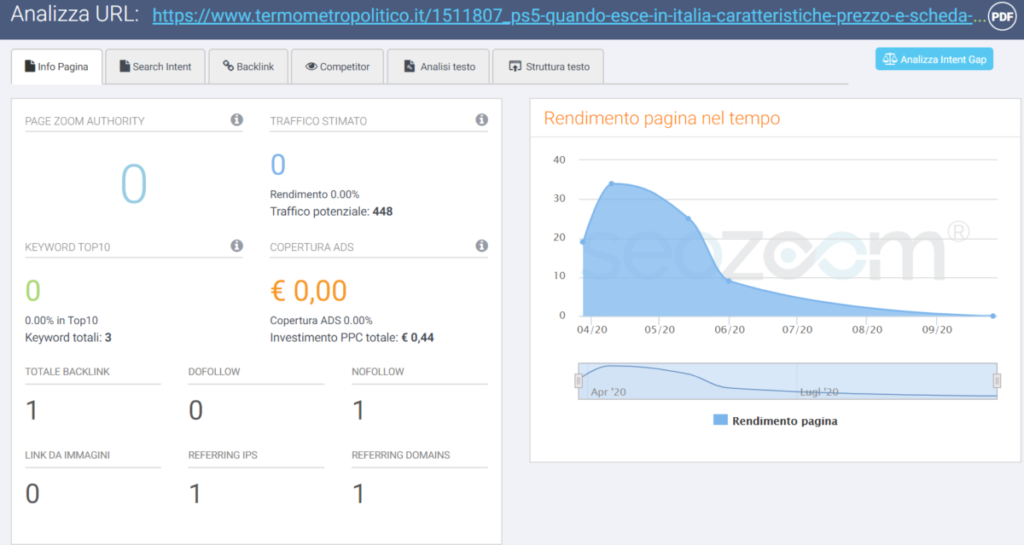
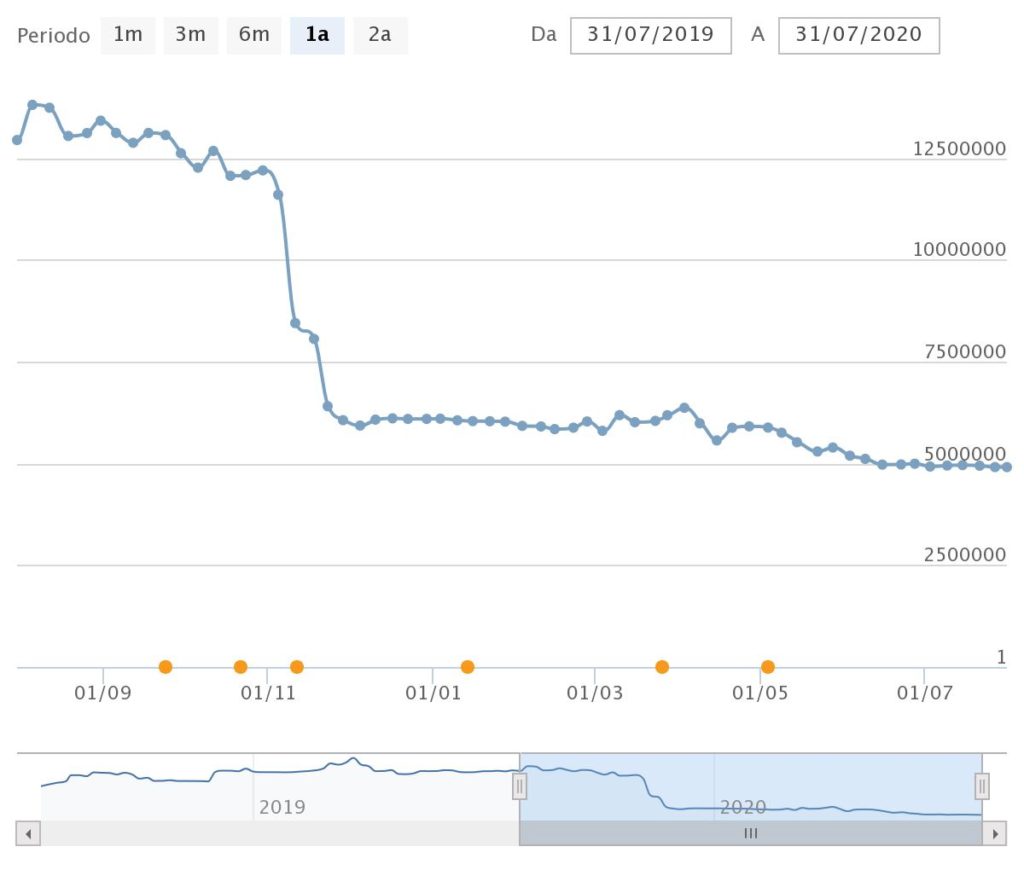
Questa ostinazione a spingere ogni minima notizia medica in modo eccessivo è chiarissima per chi, sfortuna sua, conosce marketing, SEO, KPI e in generale il mondo metrica-dipendente delle attività di comunicazione digitale. Bisogna guardare, o immaginare di poter guardare, non ci vuole poi molta fantasia, ai bilanci e alle metriche dei grandi network editoriali. I siti di informazione stanno affrontando una crisi strutturale. I dati dimostrano che la reach organica è in picchiata ormai da anni (fra le numerose cose che dovrò fare prima o poi c’è senza dubbio un ragionamento su quanto sia stato intelligente e lungimirante affidare la gran parte del proprio core business a piattaforme e aggregatori esterni, ma come sempre mi dilungherei troppo).
Reach in picchiata, dicevamo, E quando l’algoritmo di una piattaforma taglia la visibilità delle pagine, la reazione immediata dei “professionisti”, purtroppo non solo di quelli dell’ultimo minuto, è purtroppo sempre la stessa: pubblicare di più e alzare i toni a completo discapito del vero dialogo e della qualità dei contenuti. Lascia stare, per carità, che ci siano pure studi e report che spiegano come la redditività non cresca in modo lineare con le pageview:, sia mai che gli rovini qualche certezza.
Questo comportamento è figlio di due problemi: la scarsa comprensione delle metriche e di una eredità pesante. Nelle settimane più critiche della prima ondata del 2020, l’Italia era ufficialmente la nazione con il tasso di crescita più elevato in Europa per la produzione e la fruizione di informazione online, come registrato nel report ufficiale dell’Osservatorio Speciale dell’AGCOM. Eravamo il paese europeo più saturo di notizie sanitarie. Quella saturazione temporanea ha creato un precedente che ha drogato le metriche interne degli editori.
Oggi che le piattaforme Big Tech riducono costantemente l’invio di traffico verso i siti esterni, come racconta il report globale del Reuters Institute Digital News Report, i publisher si trovano nel bel mezzo di una crisi d’astinenza da click. Questo calo sistematico li sta costringendo a trucchetti algoritmici estremi pur di strappare una visualizzazione basata sulla paura. Tutto questo, ignorando quello che dovrebbe essere chiaro a qualsiasi professionista: scorciatoie e sotterfugi sono destinati a funzionare sempre meno. Eppure sono convinto che ogni mattina c’è qualcuno che si alza, guarda la lista dei dieci articoli più visti di sempre sulla sua testata, ne vede quattro sul Covid, e martella la redazione perché trovino un’altra malattia. Cinico? Provate a chiedere in giro a chi ha lavorato in un certo tipo di ambiente che vive di numeri e classifiche.
La reazione del lettore: l’abitudine alla paura e la disaffezione
Il vero errore strategico di questa caccia al contagio risiede, oltre nel dimostrare di avere capito poco delle dinamiche online, nella totale incomprensione della psicologia del pubblico. Le persone hanno sviluppato veri e propri anticorpi cognitivi. I dati ufficiali sul nostro mercato lo spiegano meglio di ogni mia disseranzione non richiesta: secondo la seconda edizione dell’Osservatorio annuale sul sistema dell’informazione dell’AGCOM, assistiamo a una pesante “fuga” intenzionale dalle notizie, con un italiano su cinque (il 20% della popolazione) che dichiara esplicitamente di evitare di informarsi regolarmente. Tra i fattori determinanti di questo distacco, spiccano il sovraccarico informativo, l’eccessiva negatività e la ripetitività dei contenuti.
Siamo di fronte allo stesso identico meccanismo che vizia le piattaforme di recensioni sul web: quando le valutazioni vengono fornite dagli utenti solo per assoluti estremizzati (o il locale è il paradiso in terra o è la peggiore bettola della storia), il sistema perde credibilità e le persone tendono a passare oltre. Se ogni linea di febbre tropicale viene trattata come l’apocalisse imminente, il lettore medio non clicca di più; semplicemente scappa, cancella la notifica e impara a considerare del tutto irrilevante chi grida continuamente “al lupo”. Insomma, qualcuno pensa che barattare un cliente fidelizzato con venti persone che passano a dare un’occhiata sia una buona idea (e la cosa triste è che non è così solo nell’editoria, ma anche qui divagherei troppo).
Le metriche di vanità (ancora? nel 2026?)
Nel giornalismo, così come nel digital marketing, esiste un bug sistemico duro a morire: scambiare i grandi numeri per valore reale. Molti direttori editoriali e social media manager sono rimasti intrappolati in una caccia disperata al traffico orizzontale, che alimenta una sorta di dipendenza editoriale da numeri sempre in crescita. Nasce nei titoloni clickbait e si nutre della necessità nevrotica di gonfiare i fogli di calcolo dei report settimanali, mensili e trimestrali (perché, si sa, sono l’unica cosa che interessa agli investitori, come se questa logica non avesse già fatto abbastanza danni a settori come il gaming o il cinema).
Ma c’è una dura verità di settore che va accettata una volta per tutte: il numero puro di visualizzazioni, che sia ottenuto attraverso il panico o con qualsiasi altro sotterfugio (perché di quello si tratta) non è una metrica di valore reale. Esattamente come accumulare centomila fan distanti o disinteressati non significa assolutamente nulla per la crescita sana e la sostenibilità di un’azienda, così i click rubati con l’allarmismo non creano lettori fidelizzati, non generano abbonamenti e distruggono l’asset più importante di una testata: l’autorevolezza oggettiva. Alimentare la news fatigue e tradire il pubblico pur di salvare i report di traffico del mese è una scelta strategica suicida a lungo termine.
Come sopravvivere alla carestia del traffico
Quando il digitale complica l’accesso all’informazione e la corretta comprensione della realtà invece di semplificarla, significa inevitabilmente che si sta sbagliando qualcosa. Non possiamo pensare che la via d’uscita per l’editoria sia inventarsi la prossima pandemia: si dovrebbe cambiare radicalmente modello mentale.
Per sopravvivere al crollo della visibilità organica e alla disaffezione, la regola d’oro è smettere di ragionare in modo puramente dipendente dalle bacheche delle piattaforme terze e mettere finalmente al centro della strategia i propri owned media. Bisogna tornare a costruire relazioni stabili, newsletter curate, applicazioni proprietarie e spazi in cui il valore del contenuto sia indispensabile e non basato sulla leva emotiva della paura.
Cari editori, rassegnatevi: la festa del traffico facile del 2020 è finita e non ci sarà alcun sequel. Smettetela di annoiare le persone con la costante ricerca della malattia del giorno e tornate a fare l’unica cosa che vi terrà in vita: informare con onestà.
Cosa ne pensi?
Pensi anche tu che l’informazione digitale sia rimasta intrappolata nel loop del sensazionalismo? I dati AGCOM sulla fuga dalle notizie rispecchiano le tue abitudini di lettura attuali? Parliamone nei commenti.