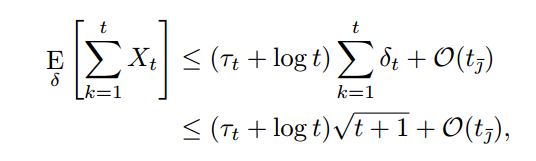L’integrazione di NotebookLM in Gemini è un segnale di lungimiranza: il miglior sistema basato sui IA per lo studio è un ottimo punto di ingresso
Siamo onesti: se oggi fuori dalla cerchi degli addetti ai lavori chiediamo a qualcuno se conosce un’intelligenza artificiale, la risposta predefinita è ChatGPT. OpenAI sta senza dubbio godendo del vantaggio competitivo che si è costruito con la copertura mediatica di qualche anno fa. Altri attori, come Claude, Midjourney e anche Copilot per certi versi, hanno saputo ricavarsi uno spazio. Nei primi anni dell’era AI, Google sembrava inseguire, affannata nel tentativo di rincorrere un treno partito in anticipo, anche se va detto che Gemini sembra evolversi con un ritmo più sostenuto degli altri. Quello che non abbiamo considerato è che Mountain View possiede già il metodo di studio, di archiviazione e i dati dei nuovi utenti. Non quelli che arriveranno fra un mese, quelli che arriveranno fra anni.
Il mercato della fretta contro la strategia del tempo
La maggior parte dei player attuali sembra ossessionata dai dati del trimestre (lo so, con gli investitori funziona così). Devono dimostrare crescita, potenza di calcolo, nuovi record di parametri. Google, con una lungimiranza che raramente si vede nel settore tech frenetico di oggi, sta invece guardando a chi userà questi strumenti tra cinque o dieci anni. Apparentemente lontana dalla battaglia della performance pura di oggi, sembra concentrata su quella dell’abitudine domani. Una strategia silenziosa, Google non è mai stata propensa ai grandissimi proclami, che passa attraverso strumenti che i professionisti di oggi spesso ignorano, ma che gli studenti hanno già adottato in massa.
NotebookLM è il più efficace ed elegante dei walled garden
Se non avete mai aperto NotebookLM (davvero?), dovreste farlo per capire il gioco in corso. Lo dico senza mezzi termini: per lo studio e per l’insegnamento è fenomenale, a mani basse, il miglior strumento per lo studio e la didattica attualmente sul mercato, meglio di molte fuffe a pagamento che fanno le stesse cose peggio. Carichi documenti, manuali, appunti, registrazioni aiudio e l’IA diventa un tutor che lavora esclusivamente sul tuo materiale. Per uno studente, ma anche per un docente è uno strumento indispensabile, uno di quelli che ti cambiano concretamente il modo di preparare un esame.
Ma non solo. Hai presente il il PDF lercio che usi come dispensa dal 2006? Lo carichi su NotebookLM e te lo trasforma in tutto: slide nuove, infografiche, video e chi più ne ha più ne metta.
Ma cosa c’entra con la concorrenza?
Senza inseguire la rivoluzione a tutti i costi, l’integrazione tra Gemini e NotebookLM è una scelta funzionale di un’efficacia disarmante. Google sta smettendo di inseguire gli altri player sul terreno dei fuochi d’artificio per giocare sul suo campo preferito: l’onnipresenza (e il vendor lock-in, ma questa è un’altra storia). Si tratta di un primo passo verso la creazione di un ecosistema dove la nostra conoscenza personale diventa il motore del chatbot principale. Per molti può sembrare un dettaglio, ma è molto di più. Impariamo dalla storia: la Gmail all’inizio era solo una mail comoda e generosa con lo spazio, ma sul lungo termine è diventata il punto di accesso dell’identità digitale di miliardi di persone. Sarò solo io, ma l’impressione che ho è che NotebookLM farà a Google lo stesso servizio.
Allevare i professionisti del futuro
Il colpo di genio è tutto qui. Uno studente che per anni organizza la sua intera vita accademica su NotebookLM, trovando tutto già pronto e indicizzato dentro Gemini, non avrà alcun motivo per cambiare ecosistema una volta entrato nel mondo del lavoro. Google sta educando i suoi utenti futuri mentre sono ancora sui libri. È un approccio che scavalca le logiche trimestrali per costruire un dominio basato sulla pigrizia cognitiva e sulla comodità operativa. Insomma, sul fatto che scegliamo sempre il percorso di minore resistenza e prediligiamo quello che conosciamo già.
Certo, a nessuno piace essere vincolato. Ma ormai è una prassi consolidata: i takeout sono faticosi, laboriosi e richiedono tempo, ed è molto difficile che le persone li facciano se non ci sono ragioni di rottura: fino a quando Google offrirà strumenti di un certo livello qualitativo, ha tutte le carte in regola per vincere la gara dell’Intelligenza Artificiale sulla lunga distanza, senza sprint: le basterà aspettare che i suoi utenti crescano.
I sistemi di raccomandazione, o algoritmi di raccomandazione, sono onnipresenti in qualsiasi sito o servizio mediamente evoluto. Con conseguenze dirompenti, e non sempre positive, sulla nostra vita.
Alzi la mano chi non è mai incappato in un suggerimento su un sito di shopping, su un trending topic o su un post ampiamente condiviso e si è chiesto perché vedo questa roba?
La risposta è semplice: algoritmi di raccomandazione. I sistemi di raccomandazione sono ampiamente usati, dai servizi maggiori ma anche quelli minori (anche questo sito ne ha uno a fondo pagina che suggerisce altri articoli potenzialmente interessanti).
I motori di raccomandazione sono ovunque
Una premessa: questa riflessione, come accade spesso, non è farina del mio sacco, ma è ampiamente riportata da questo interessante articolo di Wired USA, che spiega, in modo semplice e chiaro, il funzionamento, e soprattutto i limiti, degli algoritmi di raccomandazione. Consiglio a chiunque mastichi l’inglese di leggere l’originale, ma ne riporto qui un sunto dei concetti fondamentali. Per comodità, la “narrazione” dell’articolo originale ha uno sfondo diverso. Il resto sono mie considerazioni
Il primo problema degli algoritmi di raccomandazione è che tendono all’autoreferenzialità
Tutto parte dall’autore che nota un libro quantomeno peculiare indicato fra quelli “caldi” suggeriti da Amazon. Le vendite si sono impennate quando il libro è finito nel carosello dei suggeriti, il che ha portato una crescita dell’interesse e così via.
Beh, questo è abbastanza semplice da capire: quando un prodotto o un tema diventano trending, vengono mostrate a più persone. Il che ne aumenta le possibilità di essere visualizzato. Il che aumenta le discussioni in merito. Visualizzazioni, discussioni e feedback sono i tre pilastri degli algoritmi di raccomandazione di questo tipo. Questa è una debolezza notevole, perché una volta entrati, si crea un circolo di crescita praticamente esponenziale. E lo sforzo marginale per rimanerci , specie se si tratta di prodotti, è relativamente basso.
“Everywhere you look, recommendation engines offer striking examples of how values and judgments become embedded in algorithms and how algorithms can be gamed by strategic actors.“
“Ovunque guardi, i motori di raccomandazione offrono esempi lampanti di come valori e giudizi vengono inclusi negli algorimti e come gli algorimi possono essere manipolati dagli attori strategici”
Il secondo problema dei motori di raccomandazione è che sono imprecisi
Uno dei sistemi di raccomandazione più diffusi è basarsi su quello che le persone “come noi” hanno letto, guardato o acquistato. Ma cosa significa esattamente “come noi”? Si tratta di una questione di età, genere, razza? Gente con gli stessi interessi? Che ci somiglia fisicamente? O piuttosto si tratta delle nostre “fattezze digitali” basate sui dati granulari che i diversi sistemi raccolgono su di noi e poi dati in pasto a un sistema di machine learning?
Insomma, le persone come noi, sono semplicemente persone con una impronta digitale simile alla nostra. Il che spesso si riduce a quelle accettabilmente simili, che è un modo carino per dire che i sistemi prendono su i dati più simili che hanno. Non serve avere un dottorato di ricerca in statistica per capire che in mancanza d’altro, useranno dati con pochissime cose in comune.
Il terzo (e più grave) problema è che gli algoritmi di raccomandazione favoriscono gli stereotipi
“Deep down, behind every “people like you” recommendation is a computational method for distilling stereotypes through data.“
“Scavando a fondo, dietro ogni algoritmo del tipo “le persone come te”, c’è un metodo computazionale per distillare stereotipi attraverso i dati.
Ricordiamo un concetto fondamentale: gli algoritmi non sono nostri amici, sono macchine pensate per massimizzare il ricavo. E per ragioni meramente statistiche, tenderanno sempre a proporci quello che “il mercato” sembra volere. Quello che cambia è la dimensione della nicchia che viene presa come riferimento, a seconda di quanti dati abbiamo già regalato al sistema di profilazione.
Il passaggio successivo è meramente logico: “statisticamente probabile” e “stereotipo” sono simili in maniera preoccupante, quantomeno nelle logiche di mercato.
La prova, possiamo averla tutti i giorni, e ne ho già parlato quando suggerivo di ingannare gli algoritmi quando prepariamo un computer per “anziani” o per utenti poco esperti. Basta avviare un processo di selezione per fare in modo di ricevere quasi solo suggerimenti provenienti dalla nicchia di riferimento. Oppure (peggio ancora) un mix delle nicchie di riferimento calcolate e di temi “caldi” scelti sulla base di parametri estremamente volatili.
Infine, gli algoritmi di raccomandazione privilegiano il sensazionalismo
“…most trending-type recommendation algorithms employ a logic that filters out common terms as background noise and highlights those that have acceleration and velocity on their side.”
“…molti algoritmi di raccomandazione basati sui trend usano una logica che filtra i termini comuni come rumore di fondo e mettono in evidenza quelli che hanno accelerazione e velocità dalla loro parte”
Il problema è che questo seppellisce di fatto qualsiasi tipo di conversazione che abbia un grande volume costante nel tempo. Per esempio nel caso della cronaca i problemi costanti come la salute, il welfare, l’impiego, pur essendo oggetto di moltissime conversazioni, lasciano ampio spazio agli eventi più rari, che ottengono una copertura sproporzionata.
Ironicamente, osserva l’autore, questo è un problema in comune con la carta stampata. Come a dire che di tutto quello che i nuovi media potevano ereditare da quelli tradizionali, hanno preso il peggio.
La parte peggiore è che questo tipo di algoritmi di raccomandazione è estremamente debole e manipolabile.
Il problema di usare l’accelerazione mediatica come valore è che è fin troppo semplice manipolare l’algorimo. Un hashtag o una notizia condivisi dal giusto numero di persone in un tempo sufficientemente rapido, diventeranno virali con molta facilità. Alcuni attivisti di diverse aree hanno già imparato a mettere in pratica questa strategia, preparando interventi con lo stesso hashtag (nell’ambito di Twitter) e postandoli in modo coordinato.
Ma se funziona per Twitter, perché non dovrebbe funzionare anche in altri ambiti? Se per esempio cinquemila fan di un autore (o diecimila attivisti di qualche schieramento) si coordinano per effettuare lo stesso acquisto su Amazon nello stesso momento, quale può essere l’accelerazione conferita al prodotto acquistato?
Una domanda più che lecita perché, se davvero bastasse qualche migliaio di transazioni, “finanziare” un acquisto coordinato potrebbe essere un investimento strategico più efficace di quelli tradizionali.
La soluzione? Rendere gli algoritmi di raccomandazione più trasparenti. O eliminarli del tutto.
Grandi problemi ed enormi limiti, che tuttavia hanno soluzioni piuttosto semplici. Le aziende sono molto gelose del funzionamento dei loro algoritmi. Il sospetto che tale riservatezza nasconda il timore che possa crollare il castello di carte è più che lecito. Se ci fosse più trasparenza nell’indicazione di quello che è “trending” o “consigliato”, sarebbe più semplice per chi vede le proposte decidere cosa fare.
Così come sarebbe quantomeno doveroso, nelle piattaforme in cui sono possibili le sponsorizzazioni, che il sistema mostrasse in chiaro che percentuale della copertura del contenuto è stata a pagamento. Una specie di “certificato di nascita” che di permetta di capire se stiamo vedendo un determinato contenuto per la sesta volta perché è davvero interessante oppure perché qualcuno lo sta sponsorizzando di continuo.
L’alternativa più radicale, ma anche più semplice, sarebbe quella di eliminare gli algoritmi di raccomandazione. Ormai è chiaro che il loro funzionamento lascia molto a desiderare, e spesso non piacciono agli utenti, come dimostra il recente passo indietro di Twitter verso il semplice sistema cronologico.
Il tutto avrebbe almeno due vantaggi: il primo verso l’utente. Ammettiamolo, vedere sempre le stesse cose sapendo che una piattaforma contiene una varietà quasi infinita di contenuti è frustrante. Il secondo vantaggio sarebbe economico: invece di spendere risorse ad inseguire un sistema di raccomandazione scadente ma sempre più complesso e oneroso in termini di calcolo, si potrebbero abbattere i costi, aumentando i margini ed evitando di dovere elaborare sistemi di raccomandazionesempre più stingenti che consumano più risorse senza un reale incremento dell’efficacia. Oggi infatti le aziende investono sulla speranza che un giorno gli algoritmi inizino a funzionare sul serio.
Cosa che però sembra ogni giorno più improbabile, alla luce dei continui problemi di privacy, uso antietico dei dati e fughe di informazioni che quotidianamente minano i servizi che fanno maggiore uso degli algoritmi di raccomandazione.
Una notizia di qualche giorno fa ci raccontava di come Google Deepmind e molti altri nomi celebri del mondo dell’intelligenza artificiale stessero lavorando a una sorta di bottone rosso per le forme di intelligenza artificiale. Lo scopo, secondo le fonti più celebri, sarebbe quello di impedire alle intelligenze artificiali di perseverare in una sequenza di operazioni pericolose.
Voglio cedere al fascino per un minuto e pensare che Google, attraverso la divisione Deepmind, stia pensando a una sequenza di interruzione, se vogliamo un bottone rosso per spegnere tutto, o una safeword per quando le cose si fanno troppo estreme. E naturalmente tornano in mente Skynet che si procura da sola l’energia elettica, bombarda le superpotenze e conquista la Kamchatka, o le macchine di The Matrix e alla loro mania di giocare a farmville con gli esseri umani al posto dei pomodori.
Immaginare un tastone rosso sulla scrivania del supervisore di turno o del presidente degli Stati Uniti però è una semplificazione. Estrema. Immaginate di dover spiegare a un bambino di quattro anni come risolvere una equazione redox. Più o meno è il compito che è toccato ai divulgatori e giornalisti. Perché il documento originale è roba seria. E per roba seria, intendo di quella che ti fa tornare gli incubi degli esami di analisi, e subito dopo rimpiangere di non averla capita quando era ora.
Per fortuna, dopo 10 pagine in bilico fra piacere, dolore e schiaffi a mani aperte all’analfabetismo funzionale, ci sono delle conclusioni, probabilmente scritte in un momento di pietà per gli esseri umani che i limiti li hanno visti solo nel compito in classe di quarta superiore. Qui capiamo che lo scopo di questo documento è quello di permettere agli operatori di interrompere in modo sicuro un processo di apprendimento e assicurarsi che l’agente, cioè l’intelligenza artificiale in fase di sviluppo non imparia prevenire queste interruzioni. Inoltre il documento ci lascia con un tema affascinante.
“Una importante prospettiva futura è di considerare interruzioni pianificate, dove l’agente è interrotto ogni notte alle 2 del mattino per un’ora, o avvisato in anticipo che avverrà un’interruzione in un momento preciso”
Se volessimo fare una lista di tutte le opere Sci-Fi (e non solo) in cui il dilemma etico sulla creazione e la “educazione” delle intelligenze artificiali è un tema portante, o addirittura fondamentale, potremmo stare qui intere settimane a discuterne. L’intelligenza artificiale ha preso, nell’immaginario collettivo, il posto del robot del secolo scorso. Quello che rimane invariato, ed è un tema ricorrente, è una forma di timore ancestrale, di rivalità nei confronti della “macchina” che ha ineluttabilmente una connotazione negativa, è sempre antagonista, nemica o quantomeno ambigua e pericolosa.
Questa ve la spiego, giuro ;)
C’è chi fa risalire questo timore al primo grande shock tecnoculturale, la rivoluzione industriale. Io non sono completamente d’accordo. Ne abbiamo parlato a lungo quando con i fratelli Mercenari a Vapore si tenevano conferenze sullo Steampunk. Da Prometeo a Icaro, passando per la stessa Torre di Babele, la mitologia e la tradizione non perdono occasione per sottolineare il rapporto controverso con il progresso, con l’Artefatto. Perché, in fondo, il processo di creazione che l’uomo può mettere in atto con le proprie mani è incompleto, inanimato. E qui potrei mettere in cantiere una lunghissima dissertazione che parte dalla differenza fra la Creazione che dona la vita e la creazione incompleta figlia dell’intelletto, passando per l’alchimia per approdare ai due fratelli più improbabili della letteratura, il mostro di Frankenstein e Pinocchio, ma andrei troppo lontano dal punto. Se vogliamo ridurla ai minimi termini, il nostro cervello non si è ancora fatto una ragione di non essere in grado, dopo millenni di studi, di fare quello che ai nostri lombi costa dieci minuti di fatica. E sappiamo che l’invidia della ragione genera mostri molto più pericolosi di quelli del sonno.
Chi ha paura dell’Intelligenza Artificiale?
Tutta questa enorme tirata, apparentemente senza capo né coda, per rispondere a due domande fondamentali, che in un certo modo sono due facce della stessa medaglia: Abbiamo davvero bisogno di un interruttore di emergenza? e soprattutto, Dobbiamo avere paura dell’intelligenza artificiale?
Sì e sì
Ma per ragioni diverse da quelle più dirette.
Perché, se ci piace tanto pensare che un giorno le macchine si ribelleranno, è soprattutto colpa della coscienza collettiva. Per ora, al massimo, un’intelligenza artificiale ci ha preso a male parole. Tay, L’esperimento di Microsoft chiuso in fretta e furia a marzo, in ventiquattro ore è sfuggita al controllo ed è diventata un’entità perversa, razzista e genocida. Per fortuna era solo un bot collegato a Twitter. Ma del resto, è stata abbandonata alla mercé di Internet “per imparare a interagire con gli umani in modo più umano”. Su un Social come Twitter. Più o meno come essere buttati da un elicottero fra ultrà e polizia fuori dallo stadio “per imparare la difesa personale”. Tanto che c’erano, potevano farle un account su Tumblr e iscriverla a 4chan, poveretta. E comunque, ci ha messo molto più di Ultron, che in due minuti di Internet aveva già deciso di sterminarci.
VE LA DO IO LA “SVEGLIAAAAAA!!!1!!1!!!1111!”
Sto (nuovamente) divagando: il punto è che, mai come oggi, la realtà condiziona la finzione, e viceversa. Negli anni ’80 e ’90 avevamo le prime avvisaglie di un futuro in cui la tecnologia sarebbe passata da utilità a necessità, e poi a dipendenza. E le abbiamo riversate, come accade sempre, nelle opere di fantasia. Cito solo, ma l’elenco sarebbe eterno, Wargames: giochi di guerra, Terminator, Robocop e The Matrix perché sono i primi che vengono in mente a tutti, ma allargando appena un po’ l’orizzonte nel tempo e nelle tematiche, includere tutto quello che va da HAL 9000 a Christine – La macchina infernale è fin troppo semplice.
Oggi, quel timore ancestrale che abbiamo riversato nell’immaginario, torna a galla, molto più forte di quello che possono averci lasciato Corto circuito o Weird Science, che comunque avevano i loro risvolti dark. E chi ha visto quei film e ha letto quei libri da ragazzo o bambino, oggi progetta software, hardware, interfacce. E come accade, per esempio, nel design delle auto, alcune delle quali somigliano sempre più a quelle di videogiochi e fumetti, anche in questo caso, la tautologia si chiude: l’immaginario, generato dalla realtà, origina opere di fantasia, che ineluttabilmente condizionano la realtà. Come se, nel corso delle generazioni, gli archetipi tornassero a loro stessi dopo essere stati distillati dalla coscienza collettiva dell’umanità.
Quindi, sì, dobbiamo temere l’intelligenza artificiale, o meglio, dobbiamo temere il pessimo uso che l’umanità in generale sa fare degli ottimi strumenti che costruisce. Ma questo è un aspetto marginale, e tutto sommato di facile risoluzione. Il punto vero è: sì, abbiamo bisogno di un “pulsante di emergenza”. Per sentirci rassicurati e allontanarci dallo spettro di paure che appartengono al passato. In fondo, temiamo ancora il rancore degli dei contro Prometeo.
Anche ilkappa.com, come praticamente ogni sito del pianeta, usa cookie di terze parti per migliorare l'esperienza di navigazione degli utenti. Continuando la navigazione acconsenitirai all’uso dei cookieAccettaRejectMaggiori informazioni
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.